RDD exercises
- Based on http://otwartedane.pl/
- This exercise uses a file from : http://otwartedane.pl/89
- For later : https://open-data.europa.eu/pl/data/dataset?res_format=CSV
Plan
- Read file with real data
- Understand RDDDoublefunctions
- Understand PairRDDFunctions
- Brodcast avriables and more efficient joins
- learn how to debug RDD lineage
- Preventing shuffle
- How task are serialized
- PartiotinBy and coalesce
- Accumulators
Start
spark-shell --master local[8]
And then we can enter localhost:4040 --> Environment --> spark.master to verify that it has value local[8]
Exercise 1 : Read data file
val rdd=sc.textFile("/somePath/budzet-ksiegowy-2011.csv")
scala> rdd.count
res1: Long = 84
now check the content
scala> rdd.take(3).foreach(println)
ID;Rodzic;Poziom;Typ;Treść;Ogółem (tys. zł.);
999999;;a;Total;Ogółem;313344394;
01;;a;Część 1;KANCELARIA PREZYDENTA RP;171524;
Split fields
val fields=rdd.map(_.split(";"))
scala> fields.take(3)
res9: Array[Array[String]] = Array(Array(ID, Rodzic, Poziom, Typ, Treść, Ogółem (tys. zł.)), Array(999999, "", a, Total, Ogółem, 313344394), Array(01, "", a, Część 1, KANCELARIA PREZYDENTA RP, 171524))
Now let's see how to extract specific fields :
val budgets =fields.map(array => (array(0),array(4),array(5)))
scala> budgets.take(5).foreach(println)
(ID,Treść,Ogółem (tys. zł.))
(999999,Ogółem,313344394)
(01,KANCELARIA PREZYDENTA RP,171524)
(02,KANCELARIA SEJMU,430780)
(03,KANCELARIA SENATU,176212)
DoubleRDDFunctions
(Start this with quick explanation about implicit conversion)
val money=budgets.map{case(id,name,budget)=>budget}
scala> money.take(3)
res14: Array[String] = Array(Ogółem (tys. zł.), 313344394, 171524)
remove header
scala> val header=money.first
header: String = Ogółem (tys. zł.)
val moneyValuesStrings=money.filter(_ != header)
map to Double to trigger implicit conversions to RDDFunctions
scala> val moneyValues=moneyValuesStrings.map(_.toDouble)
moneyValues: org.apache.spark.rdd.RDD[Double] = MapPartitionsRDD[8] at map at <console>:33
scala> moneyValues.take(5)
res18: Array[Double] = Array(3.13344394E8, 171524.0, 430780.0, 176212.0, 88161.0)
scala> moneyValues.mean
res19: Double = 7554000.168674699
We have a mean budget and now lets find other interesting things :
scala> val minValues=moneyValues.min
minValues: Double = 6591.0
scala> val maxValue=moneyValues.max
maxValue: Double = 3.13344394E8
scala> moneyValues.histogram(10)
res32: (Array[Double], Array[Long]) = (Array(6591.0, 3.13403713E7, 6.26741516E7, 9.40079319E7, 1.253417122E8, 1.566754925E8, 1.880092728E8, 2.193430531E8, 2.506768334E8, 2.820106137E8, 3.13344394E8),Array(80, 2, 0, 0, 0, 0, 0, 0, 0, 1))
We have an outlier. It is because we have a row with budget summary.
scala> val moneyFiltered=moneyValues.filter(_ != maxMoney)
scala> moneyFiltered.histogram(10)
res33: (Array[Double], Array[Long]) = (Array(6591.0, 4841697.7, 9676804.4, 1.45119111E7, 1.93470178E7, 2.41821245E7, 2.90172312E7, 3.38523379E7, 3.86874446E7, 4.35225513E7, 4.8357658E7),Array(67, 6, 0, 4, 1, 1, 1, 0, 0, 2))
scala> moneyFiltered.max
res34: Double = 4.8357658E7
Also take a look at :
scala> moneyFiltered.stats
res36: org.apache.spark.util.StatCounter = (count: 82, mean: 3824849.024390, stdev: 9055892.308722, max: 48357658.000000, min: 6591.000000)
scala> val twoBiggest=moneyFiltered.sortBy(v=> -v).take(2)
twoBiggest: Array[Double] = Array(4.8357658E7, 4.4577087E7)
Also take a look at history of our transformations. This will be useful later :
scala> moneyFiltered.toDebugString
res35: String =
(2) MapPartitionsRDD[19] at filter at <console>:37 []
| MapPartitionsRDD[8] at map at <console>:33 []
| MapPartitionsRDD[7] at filter at <console>:31 []
| MapPartitionsRDD[5] at map at <console>:27 []
| MapPartitionsRDD[4] at map at <console>:25 []
| MapPartitionsRDD[2] at map at <console>:23 []
| MapPartitionsRDD[1] at textFile at <console>:21 []
| /home/pawel/Downloads/spark-data/budzet-ksiegowy-2011.csv HadoopRDD[0] at textFile at <console>:21 []
PairRDDFunctions
(First of all everyone should notice that operations perfomed in this section may be a little bit "artifical" and unnecessary - indeed but it for educational purposes)
scala> budgets.toDebugString
res41: String =
(2) MapPartitionsRDD[4] at map at <console>:25 []
| MapPartitionsRDD[2] at map at <console>:23 []
| MapPartitionsRDD[1] at textFile at <console>:21 []
| /home/pawel/Downloads/spark-data/budzet-ksiegowy-2011.csv HadoopRDD[0] at textFile at <console>:21 []
Remove header
scala> budgets.take(1)
res42: Array[(String, String, String)] = Array((ID,Treść,Ogółem (tys. zł.)))
scala> val header=budgets.first
header: (String, String, String) = (ID,Treść,Ogółem (tys. zł.))
scala> val withoutHeader=budgets.filter(_!=header)
withoutHeader: org.apache.spark.rdd.RDD[(String, String, String)] = MapPartitionsRDD[43] at filter at <console>:29
scala> withoutHeader.take(1)
res43: Array[(String, String, String)] = Array((999999,Ogółem,313344394))
Now let's unlock pair rdd functions
scala> val pairs=withoutHeader.map{case (id,name,money)=>(id,money.toInt) }
pairs: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[46] at map at <console>:33
Find two biggest :
val twoMostExpensive =pairs.filter{case (id,money) => twoBiggest.toSet.contains(money) }
scala> twoMostExpensive.count
res57: Long = 2
Let's try to recover full info by joining this set with original
scala> budgets.join(twoMostExpensive)
<console>:51: error: value join is not a member of org.apache.spark.rdd.RDD[(String, String, String)]
budgets.join(twoMostExpensive)
We need to extract Two elements tuple to be able to join two seets :
scala> val pairIdName=withoutHeader.map{case (id,name,money)=>(id,name)}
pairIdName: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[51] at map at <console>:31
scala> val result=pairIdName.join(twoMostExpensive)
result: org.apache.spark.rdd.RDD[(String, (String, Int))] = MapPartitionsRDD[57] at join at <console>:52
scala> result.count
res53: Long = 2
scala> result.collect.foreach(println)
(82,(SUBWENCJE OGÓLNE DLA JEDNOSTEK SAMORZĄDU TERYTORIALNEGO,48357658))
(73,(ZAKŁAD UBEZPIECZEŃ SPOŁECZNYCH,44577087))
Now let's see DAG of the result RDD
scala> result.toDebugString
res56: String =
(2) MapPartitionsRDD[57] at join at <console>:52 []
| MapPartitionsRDD[56] at join at <console>:52 []
| CoGroupedRDD[55] at join at <console>:52 []
+-(2) MapPartitionsRDD[51] at map at <console>:31 []
| | MapPartitionsRDD[43] at filter at <console>:29 []
| | MapPartitionsRDD[4] at map at <console>:25 []
| | MapPartitionsRDD[2] at map at <console>:23 []
| | MapPartitionsRDD[1] at textFile at <console>:21 []
| | /home/pawel/Downloads/spark-data/budzet-ksiegowy-2011.csv HadoopRDD[0] at textFile at <console>:21 []
+-(2) MapPartitionsRDD[49] at filter at <console>:48 []
| MapPartitionsRDD[46] at map at <console>:33 []
| MapPartitionsRDD[43] at filter at <console>:29 []
| MapPartitionsRDD[4] at map at <console>:25 []
| MapPartitionsRDD...
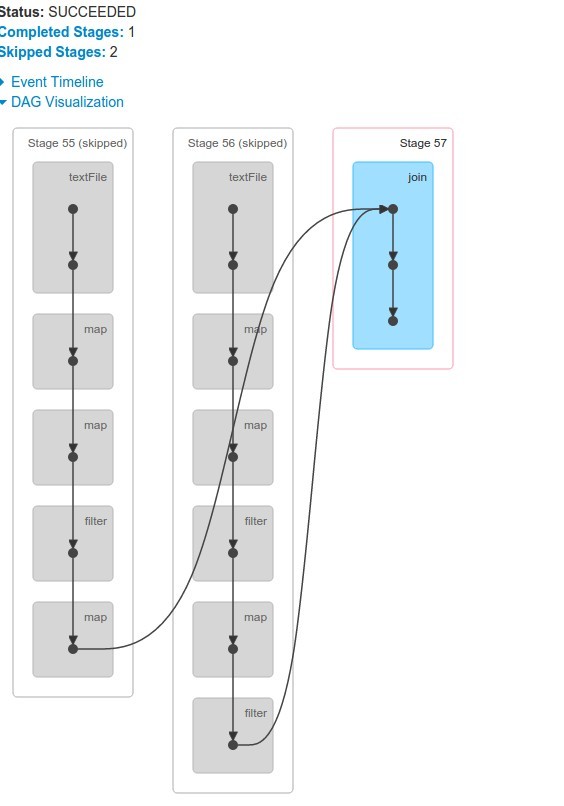
Can we somehow prevent shuffeling after join operation. Yes we can!
Brodcast variable - instead join for small sets
scala> val mostExpensiveAsMap=twoMostExpensive.collectAsMap
mostExpensiveAsMap: scala.collection.Map[String,Int] = Map(82 -> 48357658, 73 -> 44577087)
val mapBrodcasted=sc.broadcast(mostExpensiveMap)
val result2=pairIdName.filter{case (id,name) => mapBrodcasted.value.keys.toSet.contains(id)}
scala> result2.count
res61: Long = 2
scala> result2.collect.foreach(println)
(73,ZAKŁAD UBEZPIECZEŃ SPOŁECZNYCH)
(82,SUBWENCJE OGÓLNE DLA JEDNOSTEK SAMORZĄDU TERYTORIALNEGO)
And now the most important thing - was there a shuffle phase?
scala> result2.toDebugString
res63: String =
(2) MapPartitionsRDD[59] at filter at <console>:56 []
| MapPartitionsRDD[51] at map at <console>:31 []
| MapPartitionsRDD[43] at filter at <console>:29 []
| MapPartitionsRDD[4] at map at <console>:25 []
| MapPartitionsRDD[2] at map at <console>:23 []
| MapPartitionsRDD[1] at textFile at <console>:21 []
| /home/pawel/Downloads/spark-data/budzet-ksiegowy-2011.csv HadoopRDD[0] at textFile at <console>:21 []
NOOOOO - there was NOT :)
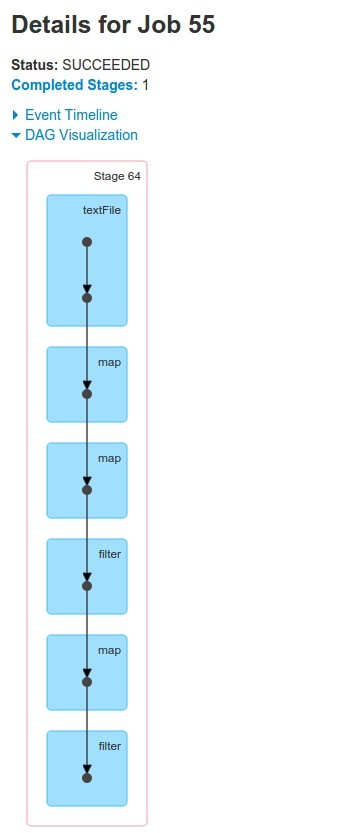
What Else triggers shuffle?
Let's do an experiment
scala> val r=new scala.util.Random
val pairs=(1 to 1000).map{_=>(r.nextInt(100),r.nextInt%100)}
scala> val rdd=sc.parallelize(pairs)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[60] at parallelize at <console>:25
scala> rdd.takeSample(false,10)
res69: Array[(Int, Int)] = Array((55,-14), (29,-91), (99,-19), (38,72), (26,-69), (64,-73), (15,-16), (92,81), (4,94), (50,66))
We see that we have some negative values. Let's change them to absolute and sum all values for given key
scala> val absoluteRDD=rdd.mapValues(Math.abs)
scala> absoluteRDD.countByKey
res81: scala.collection.Map[Int,Long] = Map(69 -> 13, 0 -> 8, 88 -> 10, 5 -> 8, 10 -> 8, 56 -> 15, 42 -> 8
scala> val reduced=absoluteRDD.reduceByKey(_+_)
scala> absoluteRDD.count
res73: Long = 1000
scala> reduced.count
res72: Long = 100
scala> reduced.takeSample(false,10)
res74: Array[(Int, Int)] = Array((23,930), (37,301), (55,561), (39,402), (66,713), (53,251), (57,466), (77,577), (85,598), (6,473))
Let's now see when data was shuffled
scala> reduced.toDebugString
res75: String =
(8) ShuffledRDD[66] at reduceByKey at <console>:29 []
+-(8) MapPartitionsRDD[64] at mapValues at <console>:27 []
| ParallelCollectionRDD[61] at parallelize at <console>:25 []
gruping instead of reducing
scala> val grouped=absoluteRDD.groupByKey
grouped: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[68] at groupByKey at <console>:29
scala> val summed=grouped.mapValues(_.sum)
summed: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[70] at mapValues at <console>:31
scala> summed.toDebugString
res80: String =
(8) MapPartitionsRDD[70] at mapValues at <console>:31 []
| ShuffledRDD[68] at groupByKey at <console>:29 []
+-(8) MapPartitionsRDD[64] at mapValues at <console>:27 []
| ParallelCollectionRDD[61] at parallelize at <console>:25 []
(relatively) A lot more data was shuffled this time - explain why.
Function serialization on executors
scala> class Context(val sc:org.apache.spark.SparkContext,val number:Int)
scala> val myContext=new Context(sc,5)
scala> val rdd=sc.parallelize(List(1,2,3,4,5))
scala> rdd.map(_+myContext.number)
org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
scala> def mapRdd(rdd:org.apache.spark.rdd.RDD[Int])={
| val local=myContext.number
| rdd.map(_+local)
| }
scala> mapRdd(rdd).collect
res92: Array[Int] = Array(6, 7, 8, 9, 10)
Partitions
more efficient joins
scala> val seq1=(1 to 100).map{i=>(i,r.nextInt(100))}
scala> val rdd1=sc.parallelize(seq1)
scala> val seq2=(1 to 100).map{i=>(i,r.nextInt(100))}
scala> val rdd2=sc.parallelize(seq2)
scala> val joined1=rdd1.join(rdd2)
scala> joined1.collect
We see that we have two RDDs and actually three stages! It's because each RDD is shuffled for join operation
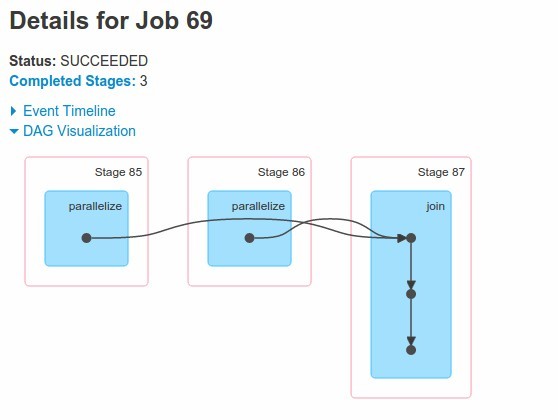
What if we have two not simmetrical data sets - can we optimize this operation in such case. Of course we can...
scala> import org.apache.spark.HashPartitioner
scala> val rdd1p=rdd1.partitionBy(new HashPartitioner(100))
scala> rdd1p.cache() // explain why we need cache here
scala> val joined2=rdd1p.join(rdd2)
scala> val joined3=rdd1p.join(rdd2)
scala> joined2.collect
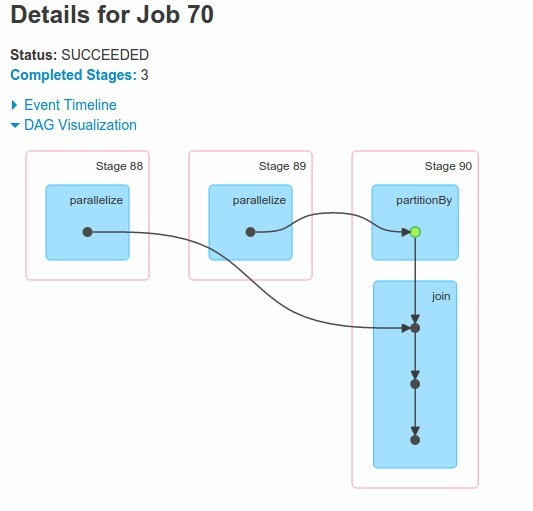
Notice that partitionBy and join are within the same stage. This mean that second dataset was transfered to nodes with first dataset - no shuffle for RDD1 !!!
now why we cached partitioned rdd?
scala> joined3.collect
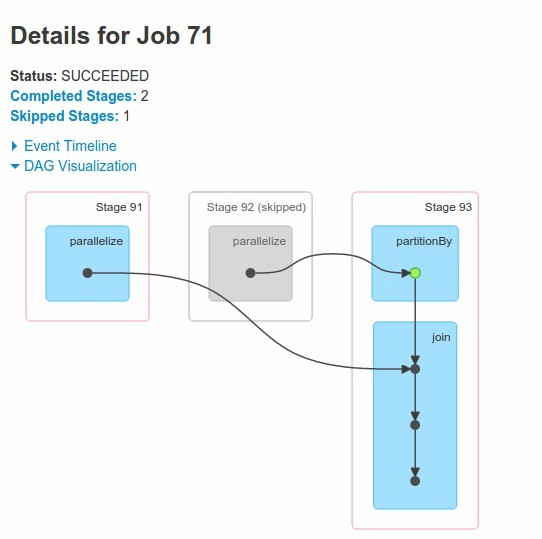
This is where we gained an advantage. Still first RDD is intact and the second one is transfered. So this solution is good for situation where one rdds changes more often than the other and join operation si repeated.
coalesce
scala> val data=(1 to 10).toList
data: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
//use 10 partitions
scala> val rdd=sc.parallelize(data,10)
We can check on how many partitions given rdd is splitted
scala> rdd.partitions.size
res96: Int = 10
scala> val rdd2=rdd.filter(_ >7)
scala> rdd2.partitions.size
res99: Int = 10
So now we have 3 elements on 10 partitions - not very effective
scala> val rdd3=rdd2.coalesce(3)
rdd3: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[85] at coalesce at <console>:27
scala> rdd3.partitions.size
res103: Int = 3
scala> rdd3.collect
res104: Array[Int] = Array(8, 9, 10)
Accumulators
Explain how Accumulators work in Spark
Simple Accumulator
scala> val simpleAccumulator=sc.accumulator(0, "simple")
simpleAccumulator: org.apache.spark.Accumulator[Int] =
scala> val rdd=sc.parallelize(1 to 10000,16)
scala> rdd.foreach(_=>simpleAccumulator.add(1))
scala> simpleAccumulator.value
res112: Int = 10000

accumulable collection
scala> import scala.collection.mutable.MutableList
scala> val collectionAccumulator=sc.accumulableCollection(MutableList[Int]())
scala> rdd.foreach(e=>collectionAccumulator += e)
collectionAccumulator.value
res115: scala.collection.mutable.MutableList[Int] = MutableList(3126, 3127, 3128, 3129, 3130, 3131, 3132, 3133, 3134, 3135, 3136, 3137, 3138, 3139, 3140, 3141, 3142, 3143, 3144, 3145, 3146, 3147, 3148, 3149, 3150, 3151, 3152, 3153