Start
- Downlaod Spark from https://spark.apache.org/docs/latest/index.html
- Run First example /bin/run-example SparkPi 10
~/bin/Spark$ bin/run-example SparkPi 10
15/07/17 00:12:19 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/07/17 00:12:19 WARN Utils: Your hostname, maszyna resolves to a loopback address: 127.0.1.1; using ---------- instead (on interface eth0)
15/07/17 00:12:19 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Pi is roughly 3.141192
- Check Local Mode ./bin/spark-shell --master local[2]
scala> val rdd=sc.parallelize(List(1,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:21
scala> rdd.reduce(_+_)
res2: Int = 6
- You can also complete quick start section : https://spark.apache.org/docs/latest/quick-start.html
less logs
Put into $SPARK_HOME/conf/log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
Exercise 1 - RDD - Creation,Actions and Transformations
- Understand what is RDD
- Transformations and Actions
- What are workers
- What are partitions
- Relations between workers and partitions
- What is the Driver and what is executed by workers
Start spark console - local[4] means that we will use 4 local workers. Each worker can process data independently.
bin/spark-shell --master local[4]
execute :
val rdd=sc.parallelize(1 to 16)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
discussion : what is an RDD
discussion : why there is nothing in webUI?
execute :
scala> rdd.collect()
res0: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)
Check UI :
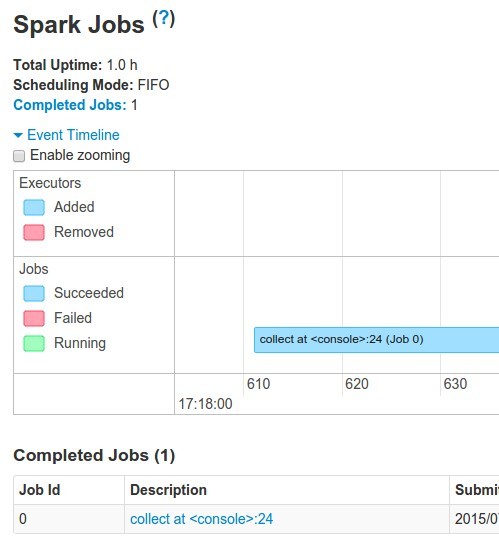
discussion : what just happened?
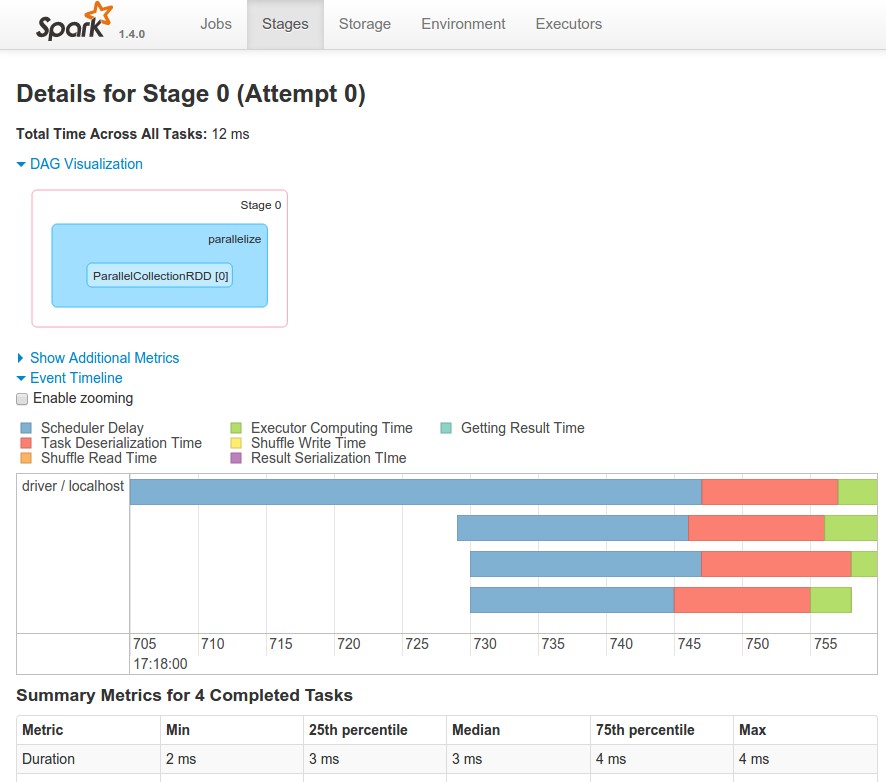
execute :
scala> val rdd2=sc.parallelize(1 to 16,4)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:21
scala> rdd2.collect()
res1: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)
execute :
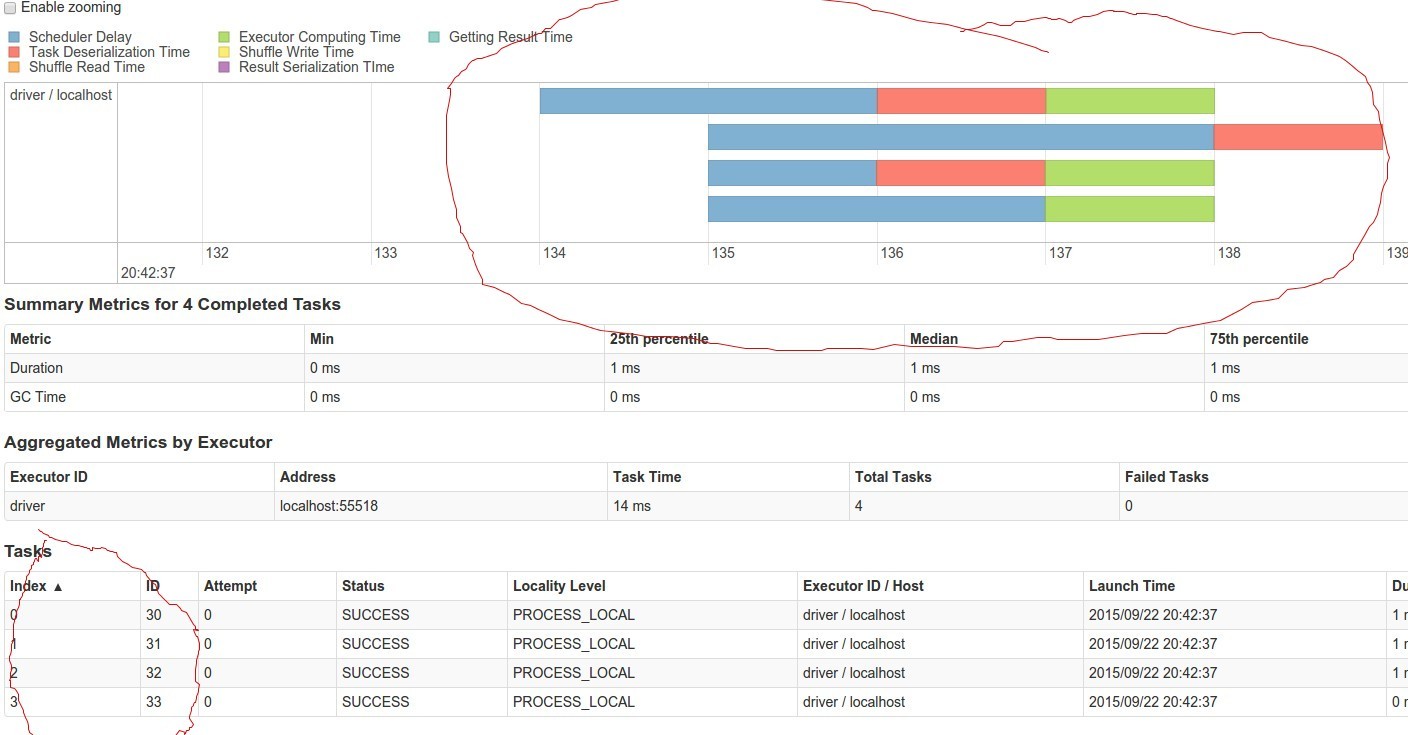
scala> val rdd3=sc.parallelize(1 to 1600,4)
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:21
scala> rdd3.reduce(_+_)
res6: Int = 1280800
scala> val rdd4=sc.parallelize(1 to 1600,7)
rdd4: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:21
scala> rdd4.reduce(_+_)
res7: Int = 1280800
Exercise 2 - RDD Transformation
scala> rdd2.collect()
res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)
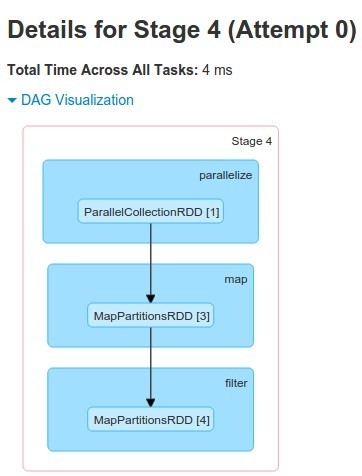
scala> val rdd4=rdd2.map(arg=>arg+1)
rdd4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:23
scala> val rdd5=rdd4.filter(_ % 2==0)
rdd5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at filter at <console>:25
scala> rdd5.collect()
res4: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16)
Exercise 3 - File Reading
execute :
scala> val wrongRDD=sc.textFile("WRONG_FILE")
wrongRDD: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at textFile at <console>:21
Everything seems to work fine but...
scala> wrongRDD.count()
org.apache.hadoop.mapred.InvalidInputException: ....

execute:
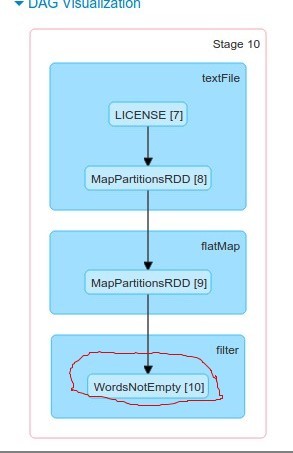
scala> val goodRDD=sc.textFile("LICENSE")
goodRDD: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[8] at textFile at <console>:21
scala> goodRDD.count()
res6: Long = 952
scala> val words=goodRDD.flatMap(_.split(" "))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[9] at flatMap at <console>:23
scala> words.count()
res7: Long = 9599
scala> words.take(5)
res9: Array[String] = Array("", "", "", "", "")
Check UI console. Then execute :
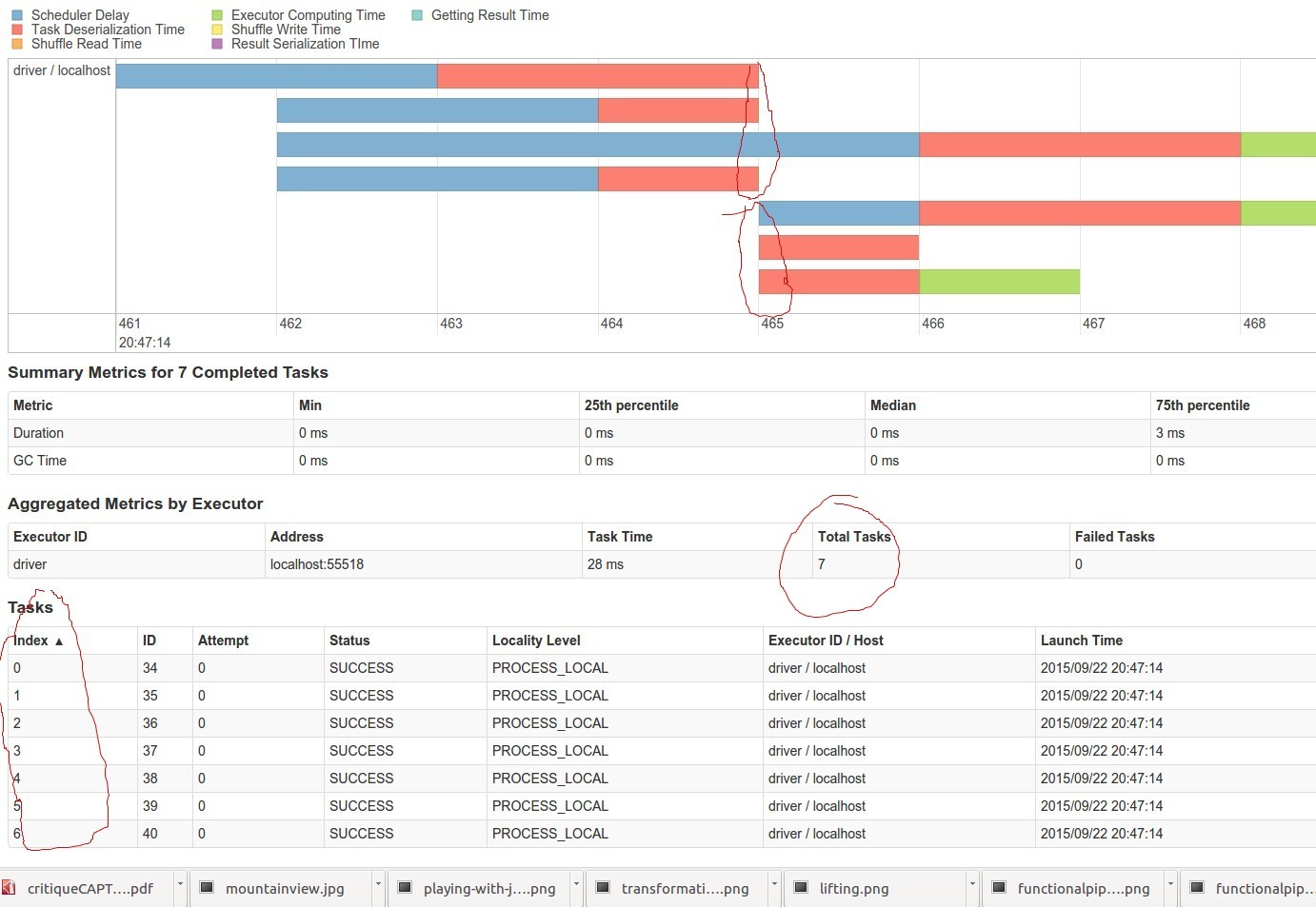
scala> val notEmptyWords=words.filter(_!="")
notEmptyWords: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[10] at filter at <console>:25
scala> notEmptyWords.setName("WordsNotEmpty")
res12: notEmptyWords.type = WordsNotEmpty MapPartitionsRDD[10] at filter at <console>:25
scala> notEmptyWords.count()
res13: Long = 6802
execute :
val pairWords=notEmptyWords.map(word=>(word,1))
pairWords: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[11] at map at <console>:27
scala> val reduced=pairWords.reduceByKey(_+_)
reduced: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[12] at reduceByKey at <console>:29
scala> reduced.takeSample(false,5)
res14: Array[(String, Int)] = Array((USING,,1), ((net.sf.py4j:py4j:0.8.2.1,1), ("submitted",1), (bound,3), (core,2))
This is first time when we have two stages. Why and what are the consequences?
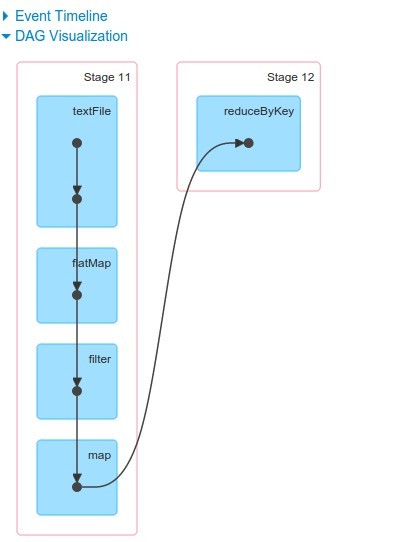
Scala Note Start: There is no method "reduceByKey" in https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RDD".
Where is it taken from?
Scala Note End
Now take 10 most frequent words
scala> reduced.sortBy{case (w,c)=> -c}.take(10)
res24: Array[(String, Int)] = Array((#,279), (the,279), (of,154), (to,127), (and,126), (or,124), (OR,124), (OF,102), (in,89), (THE,69))
We need to do it once again. REPL Driven Development :
scala> val stopWords=Set("the","to","of","and","in")
stopWords: scala.collection.immutable.Set[String] = Set(in, to, of, and, the)
scala> val fullWords=notEmptyWords.map(_.toLowerCase).filter(word => !stopWords.contains(word) )
fullWords: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[35] at filter at <console>:29
scala> fullWords.take(20)
res26: Array[String] = Array(apache, license, version, 2.0,, january, 2004, http://www.apache.org/licenses/, terms, conditions, for, use,, reproduction,, distribution, 1., definitions., "license", shall, mean, terms, conditions)
Broadcast variable
val stopWordsBs=sc.broadcast(stopWords)
scala> val fullWords=notEmptyWords.map(_.toLowerCase).filter(word => !stopWordsBs.value.contains(word) )
fullWords: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[39] at filter at <console>:31
scala> fullWords.take(20)
res27: Array[String] = Array(apache, license, version, 2.0,, january, 2004, http://www.apache.org/licenses/, terms, conditions, for, use,, reproduction,, distribution, 1., definitions., "license", shall, mean, terms, conditions)
execute :
val result=fullWords.map((_,1)).reduceByKey(_+_).sortBy{case(w,c) => -c}
result: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[48] at sortBy at <console>:33
result.take(100)
res31: Array[(String, Int)] = Array((#,279), (or,248), (any,111), (this,94), (for,86), (copyright,65), (license,64), (a,64), (software,56), (not,50), (by,49), (is,48), (that,47), (conditions,44), (-,44), (be,43), (with,40), (shall,39), (without,38), (psf,38), (python,37), (use,36), (provided,35), (========================================================================,34), (derivative,34), (following,33), (yes,33), (on,32), (source,32), (you,32), (work,32), (are,31), (may,28), (other,27), (under,27), (but,27), (such,27), (agreement,24), (as,24), (no,24), (limited,22), (license),22), (all,22), ((c),21), (terms,21), (form,20), (license.,20), (an,20), (warranties,19), (damages,19), (express,19), (use,,19), (contributors,18), ("as,18), (purpose,18), (notice,18), (must,18), (liability,,18),...
And the final flow looks like this :
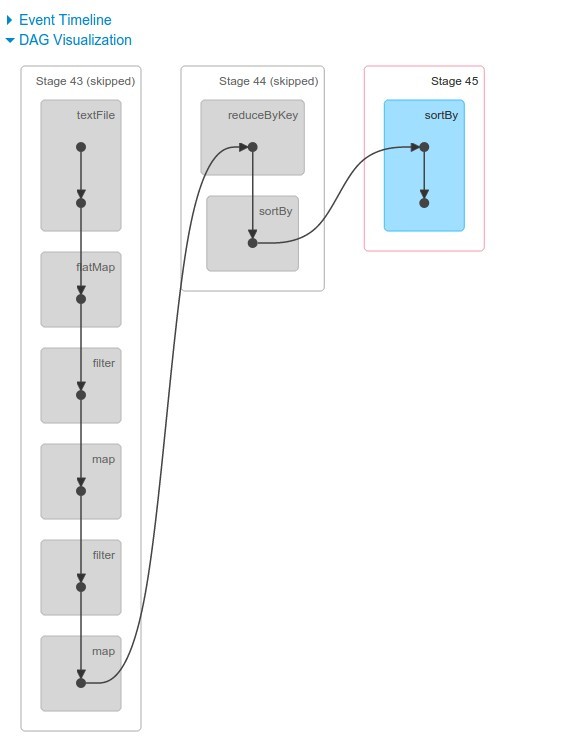
Caching
Bad News - each operations till now trigerred reading from file over and over again. Why?
execute :
scala> val goodRDD2=sc.textFile("LICENSE")
goodRDD2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[51] at textFile at <console>:21
scala> goodRDD2.cache()
res32: goodRDD2.type = MapPartitionsRDD[51] at textFile at <console>:21
scala> goodRDD2.count()
res33: Long = 952
goodRDD2.collect()
res34: Array[String] = Array("", " Apache License", " Version 2.0, January 2004", " http://www.apache.org/licenses/", "", " TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION", "", " 1. Definitions.", "", " "License" shall mean the terms and conditions for use, reproduction,", " and distribution as defined by Sections 1 through 9 of this document.", "", " "Licensor" shall mean the copyright owner or entity authorized by", " the copyright owner that is granting the License.", "", " "Legal Entity" shall mean the union of the acting entity and all", " other entities that control, are controlled by, or are under common", " control with that entity. For the purpos...

Cacheed RDDs will be green in UI

Spark In IDE
Works on my machine :
build.sbt
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "1.4.0" % "provided",
"org.apache.spark" %% "spark-sql" % "1.4.0" % "provided"
)
code
object HellloSpark {
def main(args: Array[String]) {
val sc: SparkContext = createContext
val rdd = sc.parallelize(List(1,2,3,4,5,4))
val result=rdd.reduce(_+_)
println(result)
}
def createContext: SparkContext = {
val conf = new SparkConf().setMaster("local").setAppName("nauka")
new SparkContext(conf)
}
}
----------------BONUS
- Accumulators